写写作业,记记笔记(maybe
Reflections on Trusting Trust——KEN THOMPSON
主要内容
吹水部分提到了Dennis Ritchie(C语言之父),他俩有一次写了个20行 逐字符 相同的汇编程序(磕到了)
程序员这个职业是Ken写在个人收入申报表上的职业,因此他介绍了他写过的最好玩的一个程序
- Stage1:写出最短的编译运行后能够生成自己源码的程序
- Stage2:learning program的思路是教会编译器如何处理给定的字符
- Stage3:当编译器匹配到某个pattern时,编译出bug
以上步骤组合起来,修改编译器编译出bin、安装为库后,再恢复为正常的编译器,由于程序是可复制的,后续所有采用该库编译的代码都会有bug而无迹可寻
作者给出了很有哲理的结论:You can’t trust code that you did not totally create yourself. 不要信任非自己亲手写的代码(反思自己平常用的github上star不多的代码和gpt生成的代码)
最后呼吁了媒体严肃对黑客这一群体的认识,媒体对他们的报告是“神童”,一种偏褒义的评价。然而实际上侵入计算机系统的后果最轻是故意破坏公物,最坏是非法侵入和盗窃等罪名,还是很严肃的。
思考
真的无迹可寻吗?如果反编译可执行文件,发现执行逻辑和源码不同,就会意识到程序有bug,寻找bug的源头可能会去检查编译器的版本,发现编译器没问题可能就会去查看依赖库(当然比较难找了)
Recognizing Safety and Liveness——Bowen Alpern
主要内容
安全性和活性的通俗理解:
- 安全性:坏事儿不会发生,证明满足性质是不变性论证
- 活性:好事儿最终会发生(类比区块链的活性,诚实用户的交易在一定时间后一定会出现在诚实节点的账本中),证明满足性质是良基论证
本篇论文的主要工作包括:
- 通过测试来判断一个Büchi有限状态自动机描述的性质是否满足活性和安全性
- 证明了对于确定性Büchi有限状态自动机的性质,可以用不变性论证来证明;
- 活性可以通过良基论证来证明
- 给出了活性和安全性的形式化定义
- 给出了将性质分解为活性和安全性的方法,其中活性和安全性的合取就是原始属性
Büchi有限状态自动机接受两类输入
所有第一个状态满足谓词 $\neg Pre$的无限序列
满足$Pre\ \neg Done \ Done\wedge Post$的无限序列
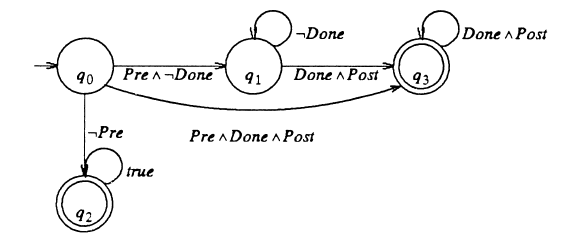
如果对每个状态存在能到接收状态的路径,称Büchi有限状态自动机是可缩减的
对于安全性的定义的理解是对于性质$P$,如果在无限序列$\sigma$中坏事发生了,一定在有限前缀后,能够符合$P$;如果$\sigma$不符合$P$,说明存在$\sigma$的某个前缀包括坏事,对于该前缀的任何扩展,都不会满足$P$。
对于活性的定义,需要观察到的是,没有任何部分执行是不可挽回的,因为如果某个部分执行是不可挽回的,那么它就是一个坏事。作者认为这是活性的定义特征。如果属性$P$满足以下条件,则$P$是一个活性属性
思考
这篇论文采用有限状态自动机来形式化地描述和验证性质,我很好奇是否存在其他的模型能够被用来形式化这些性质,以及在具体的应用场景中,比如区块链上,是否可以通过设计一个静态分析或形式化验证的工具,定义一些性质来检测区块链共识的漏洞。
Fairness Through Awareness——Cynthia Dwork
主要内容
本文研究的是分类中的公平性,主要贡献在于是提出了一个公平分类的框架
- 用于确定个体在当前分类任务中相似程度的(假设性的)任务特定度量
- 在公平约束条件下最大化效用的算法,即对待相似的个体应类似对待
本文还讨论了公平性与隐私的关系,公平性何时暗示隐私,以及在差分隐私背景下开发的工具如何应用于公平性问题。提供了一个公平分类的规范方法和一个实现公平性的框架。
思考
本文主要的idea是实现相似的人在分类中被类似地对待,讨论部分提出的在广告领域中的公平性是否会隐藏广告商的信息的问题非常有趣,从相反的视角来考虑提升公平性可能带来对隐私的破坏。(隐隐看来本文的工作非常契合西方对”政治正确”的偏好)
Notes
BLP模型中的安全等级可以更改
- 谁可以更改:安全服务的使用者
- 什么时候可以更改:$\text{收益}\leq\text{成本}$ 时不会更改
- 如何判断是否应该改?本质是上一个问题,需要量化当前的收益,cybersecurity inssurance
存在Covert Channel
完整性指信息的真实性 可靠性
可用性:信息匹配服务
安全策略的执行和验证
可扩展系统的的安全性
- 插件
- 应用
- 服务器跑脚本
可用方法
- 类型检查
- 静态验证
- 代码重构(目前国产软件的层次)
- 运行时强制执行(重点介绍)
前两个方法需要代码审计者的程序设计水平更高
利用执行监视器强制实施安全策略,只能获得程序原子操作一次执行的结果,例子
- 文件系统访问控制
- 防火墙
- 堆栈检查
- 动态边界检查
- 恶意软件检测器
- Chrome SP
审计监视策略的缺点:滞后性,只有发生事件之后才能观察到
引用监视器
机制完整性:假设输入符号对应实际执行,真实的状态转换对应于自动机的转换函数,建模可以覆盖100%的程序
解决策略
- 隔离:目标程序无法写自动机的内部表示
- complete mediation:一个变量在研究中完全传递或完全解释了两个其他变量之间的关系
如何证明程序S满足策略集合P:
当S违反任意策略时终止,否则继续运行
需要保证实施方案符合隔离、complete mediations
重写器:输入机器语言程序,输出嵌入了安全策略的程序
trusted machine learning
目前的LLM可分为预训练模型(基模型)+特定任务模型
大模型的参数增长速度远远大于摩尔定律算力的增长,无法采用静态分析类似的思想进行大模型的安全性分析,后续的工作都是抽查的思想
训练数据本身存在误差
如果训练数据没有误差是否会正确
消除幻觉
一致性
对齐:和人类社会的规则、价值观保持一致