Ji R, Xu M. Finding Specification Blind Spots via Fuzz Testing[C]//2023 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 2023: 2708-2725.
形式化验证能够证明保持验证过的程序和声明的spocifications(SPEC)保持一致,但是如何保证SPEC是完备的 没有逻辑漏洞?本文使用Fuzzing-Assisted Specification Testing来解决这个问题。
核心思路是利用形式化验证过的程序的冗余性和多想想进行交叉检查。
具体来讲,在同一个代码库中,SPEC(规范)、实现(CODE)和测试套件都是从同一组业务需求中派生出来的。因此,如果某个意图在CODE和测试用例中被捕捉到,但在SPEC中没有,则这表明SPEC存在盲点。
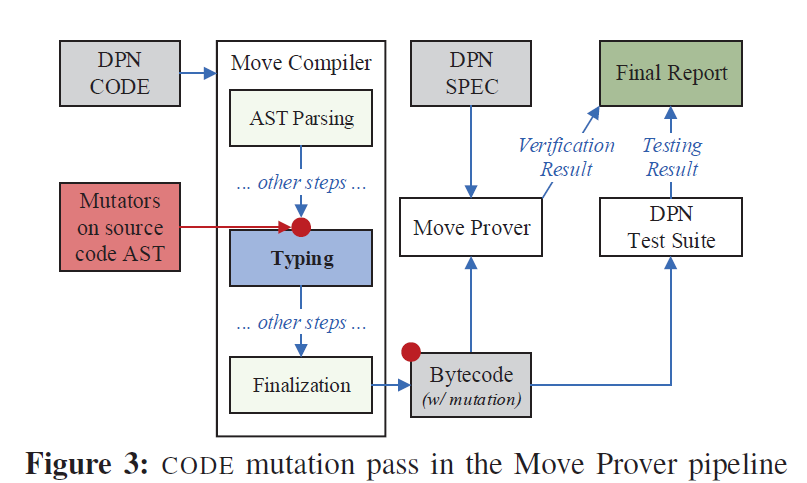
FAST以自动化的方式检查SPEC中的不完整性问题:它首先通过变异测试来定位SPEC的缺口gap,即通过检查CODE变体是否符合原始的SPEC来确定是否存在缺口。如果是这样,FAST进一步利用测试套件来推断缺口是由意图引起还是由错误引起的。根据代码库的大小,FAST可以选择以枚举方式还是进化方式生成CODE变体。FAST被应用于两个具有形式验证特性的开源代码库,并且分别帮助确认了它们SPEC中的13个和21个盲点。这凸显了SPEC不完整性在真实应用中的普遍存在。
Introduction
形式验证通过数学方法检查程序的正确性,为计算系统提供高度保证,即程序的行为完全受限于描述为一组期望属性(规范)的形式建模语言。形式验证在硬件和软件系统中已经被广泛采用。典型的应用场景包括可能导致重大损失和不可逆后果的情况(例如航空领域),或者传统的滚动式程序升级模型不可行的情况,如区块链上的智能合约。
形式化验证可以分解为两步
- 1 设计目标系统的一系列规范 SPEC
- 2 证明实际的实现 CODE 和规范 SPEC是否符合,即$SPEC \sqsubseteq CODE$
目前学术界在2方面进展迅速,但是1被关注较少。这就存在着严重的问题,即使一个程序经过完善的验证工具链进行了彻底的验证,该程序的正确性也仅限于其规范,程序中可能存在着盲点。由于目前形式化验证的成本较高、技术门槛较高,进行SPEC编写的人员一般不是写代码发的,作者想传达的思想是不能盲目的相信形式化验证后的代码,还需要去理解SPEC完备性的重要性
硬件领域对SPEC完整性的研究比较多,现有的工作基于mutation testing,即将CODE或者SPEC进行变异,检查变异体是否依然符合旧的内容,因此,任何存活的变异体都会引发一个信号,表明规范可能是不完整的
因此去可以去研究:
- 变异测试 mutation testing 是否能够应用于软件安全
- 如果不能,可以采用怎样的改进
- 优化后来解决成熟的代码库中是否普遍存在规范不完备的问题
本文的主要工作是首先确认了采用变异测试能够高效地发现SPEC的漏洞,但是对于复杂的程序,基于变异的测试不够有效
挑战
- 当mutant通过了验证,如何证明SPEC之间的gap是故意而为还是错误
- 解决思路:利用形式化验证程序中的冗余性和多样性,即代码 SPEC和测试套件都是从一组需求来的,但是以不同的思维方式进行编程:例如,使用不同的编程语言(甚至是编程范式)实现的,具有不同的演进路径,一般不同且独立的团队进行编写。因此,这三个不太可能出现相同的错误。
- 可以通过相互比较来发现错误
- 如何构造一个更容易通过验证的mutant
- 解决思路:fuzzer的遗传算法,计算每个mutant的fitness,只有高质量的mutant才可能被多次变异,fitness的标准就是验证后触发的错误(这也太trivial了)
FAST无法保证一定没有完备性问题,但可以用于说明程序中不存在明显的逻辑漏洞
贡献
本文的贡献包括
- 概念:我们指出形式验证程序中规范、代码和测试套件的“冗余性”和“多样性”,并利用这种冗余性(通过将测试套件作为“裁判”)来解决判断规范中缺陷是故意还是错误的问题,。
- 设计:采用基于遗传的进化,每个新的mutant会更难被杀死
- 如何保证输入的多样性
- 影响:分别发现了DPN和S2N中13个和21个盲点
Background and related work
介绍形式验证和规范不完整性问题以及变异测试和模糊测试
形式化验证
已经被广泛应用在软件和硬件、密码学库(HACL*)、编译器、网络协议和智能合约(diem)中
步骤
- 采用抽象逻辑语言设计SPEC
- 开发形式化工具来推理SPEC和目标代码实现之间的关系
矛盾在于,一个理想的规范集需要足够完整,能够捕捉到所有利益相关者的意图,同时又需要足够抽象,以便在实施选择方面具有灵活性。例如,如果需求是对数组排序,SPEC需要足够完备能够理解排序的语义,然而需要足够抽象能够支持快排和归并排序的实现
然而,开发一个高质量的规范集是困难的。一个与代码相对应的规范集在实际价值上几乎没有意义,只会使代码库臃肿,导致代码更改的摩擦和更高的维护成本。另一方面,如果规范过于抽象,可能无法捕捉到一些基本的设计要求,在代码中可能存在未被发现的潜在漏洞。
目前的工作都是基于启发式手动调整的checklist
自动化函数验证
本文主要聚焦于具有前置条件和后置条件的函数正确性验证,有时也被称为“按设计实现”的验证
在函数验证中,规范的目标通常是构成单个函数的代码,开发人员以SPEC谓词的形式为函数体提供前置条件和后置条件,这些谓词通常包括对函数参数和/或可以由函数中的代码引用的环境状态的条件。规范可能包含没有具体可执行语义的构造,例如对无界域的量化。虽然针对单个函数进行规定的,前置条件和后置条件不仅限于仅确立一个函数的正确性,它们对整个程序正确性的确立作出贡献,因为前置条件在调用方验证,从而可以在调用后假设后置条件。

例子中的ensures是一个后置条件,验证工具的任务是将代码和规范融合为可以交给后端求解器(通常是SMT求解器)处理的证明义务。
规范SPEC的完备性
图1中的代码符合SPEC,但是SPEC忽略了一个问题,如果add1函数的实现方式与图2a中所示,在原始循环之后还有一个额外的pop()操作。当前的规范只检查向量中每个剩余元素的值是否增加了一,忽略了对数据长度的校验。完整的规范如图2b所示,其中还有一个额外的ensures子句,进一步限制了add1函数修改输入向量的能力。这个缺失的ensures子句代表了原始规范的不完整性问题。

这里的问题出现在写SPEC实际上是另一种形式的编程,如何保证SPEC没有bug也很重要。这个问题被称为gauging the completeness of SPEC,在硬件领域受到了较多的关注,硬件领域主要采用的方法是mutation testing。
Mutation testing
mutation testing的idea来自于对软件测试的测试用例的怀疑主义,代码的安全性由测试保证,测试用例的安全性如何保证呢?这与FAST旨在解决的规范不完整性问题类似。
其实mutation based testing是从1970年代就开始被研究的一种方法
代码测试可以分为
- 单元测试
- 集成测试
- 端到端测试
用于测试不同测试组件的质量
同样可以用于测试没有具体语义的程序
硬件测试中,变异测试的目的是通过引入功能变换来评估给定的硬件SPEC的完整性。
fuzzing中的遗传策略
由于输入的状态空间较大,完全随机的输入生成实际作用不大。
在现代模糊测试研究中,处理状态探索问题的一种方式是模拟自然选择过程,结合随机变异和适者生存。具体而言,在每个变异轮次中,随机变异被用于增加探索尚未探索的路径的机会。适者生存的过程通过根据反馈(例如,在大多数模糊测试中的代码或路径覆盖)有效地对不同的种子进行排序,并给予排名较高的种子更好的机会来生成未来测试轮次的输入。
在模糊测试器的所有构建模块中(例如变异规则、种子调度、反馈机制),提供对种子质量的客观评估的度量标准对于模糊测试器的有效性至关重要。
AFL用了代码覆盖率,FAST提出了一种新的度量标准:利用求解器中的验证错误数量和多样性。
Language fuzzing好像和目前的虚拟机比较接近?语言模糊测试旨在发现编译器或解释器(例如虚拟机或JIT引擎)中的问题,这几篇可以再看一看

- Superion: Grammar-aware Greybox Fuzzing.
- Soyeon Park, Wen Xu, Insu Yun, Daehee Jang, and Taesoo
Kim. Fuzzing Javascript Engines with Aspect-preserving
Mutation. In Proceedings of the 41st IEEE Symposium on
Security and Privacy (Oakland), San Francisco, CA, May
2020. - JQF: Coverage-guided Property-based Testing in Java.
The Tale SPEC CPDE and Tests
生成多样的mutant不是挑战,评价生成的mutant的有效性是更重要的问题,本文中指通过了SPEC的mutant,在这里还需要判断这个mutant是否故意设计的gap
核心idea或者假设是:SPEC(来自于spec团队)、CODE(来自于开发者)、test suites(来自于QA质量保证团队)、三者不太可能犯同样的错,可以通过运行其中一个,和另外两个交叉对比检查正确性,实际上在测试用例中运行并检查SPEC就是一个例子
变异
类型保留的变异:为了产生有效的CODE变异体,保证至少应该能够编译和执行,不具有参考价值
枚举变异:根据表1中讨论的有限的变异规则集合,对于在原始CODE中没有太多指令的小型代码,即使用算法1中描述的算法尝试所有可能的变异策略
- 不支持一次修改多个运算符
- 改变循环结构的方法
- if else对换
- continue break对换
- 三目运算符 对换
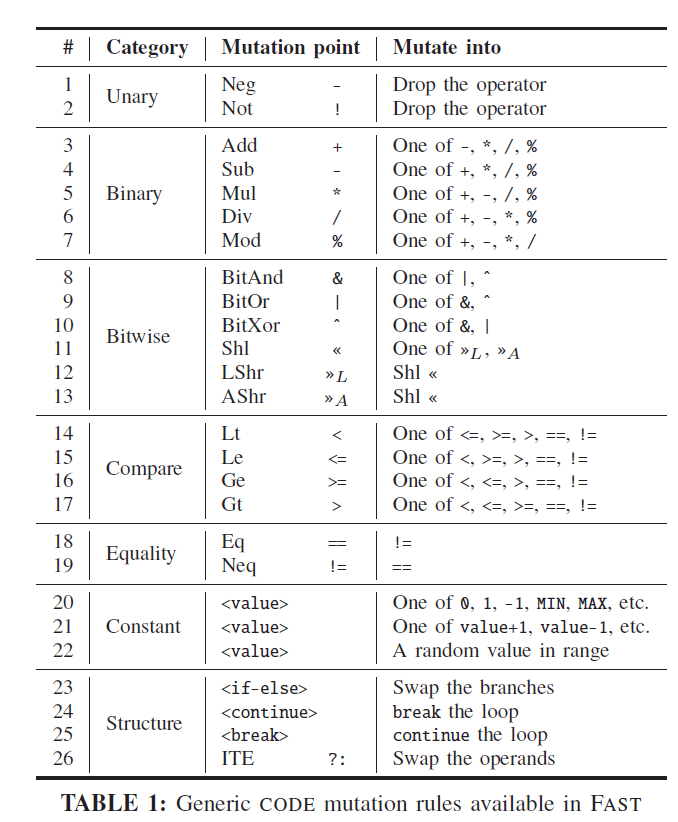

案例:Diem 支付网络
居然是区块链的例子,泪目了
- 首先,静态分析AST,寻找所有可能的变异的地方
迭代地检查每个变异点,并按照表1中的通用变异规则生成CODE mutant。对于常量变异,CODE随机选择表1中列出的三个变异规则之一作为变异目标
对于每个生成的CODE突变,FAST将其传递给证明器,与原始的SPEC一起进行验证,并检查Move证明器的验证结果。Move证明器将报告验证状态以及验证错误的详细说明,即在CODE的哪一行违反了哪个SPEC属性
结果:发现了404个可以进行变异的地方
基于遗传策略的CODE变异
问题:当代码规模过大时,不适合将所有可能的突变点进行变异
遗传算法需要回答的两个问题:
- 变异的对象
- solution:在进化开始之前,预先收集CODE中的潜在变异点。在这个信息收集步骤中,FAST从头到尾扫描给定的CODE,并将每个指令与表1中定义的可能的变异模式进行匹配
- 哪个mutant更加适合作为下一轮的种子
- 适度fitness评估:出现更少的错误,发现先前未知的验证错误均是好的mutant的表现
- SPEC覆盖率是通过CODE变异体触发的验证错误来衡量的。对于每个未通过验证的CODE变异体,FAST期望从验证器那里得到一个报告来描述失败的原因。这个报告可以是一个简单的二进制通过/失败信号,也可以是一个包含 $SPEC \ X$ 在 $CODE$ 位置 $Y$ 由于原因 $Z$ 失败的记录的元组$(X, Y, Z)$列表。信息越详细,FAST对变异体的“适应度”测量就越好。
- 幸运的是,在实践中,大多数形式化验证工具都可以给出非常详细的验证错误解释,甚至包括可以具体执行以确定错误的反例。
- CODE变异体都被分配了一个初始分数,该分数与两个因素成反比:1)剩余的验证错误数量和2)变异trace的长度。对于相同的验证错误集,FAST偏向于较小的变异体(即与原始CODE的编辑距离较小,类似于NeoDiff)
fuzz的流程
seed pool保存着有意义来进行后续变异的种子code,种子都是根据分数排序的,每轮首先是种子选择算法,排序给出当前轮的种子并进行变异
- 如果验证通过,分析是否为误报
- 如果验证失败,评估新code的适度,如果适合则保存该种子。同时,更新父种子的分数,并将父种子也加回到池子中
- 如何保证种子的多样性?多给一些CODE,初始权重一样
值得一提的是,与可以从具有许多测试用例的种子池中启动的传统模糊测试不同,FAST的种子池在开始时只有一个种子,即没有任何变异的原始CODE。FAST给予这个创世种子足够高的分数,以便快速填充种子池中大量的单变异种子。但是在引导期之后,从FAST的角度来看,这个创世种子与其他种子没有区别。
Evaluation
- 测试套件的有效性
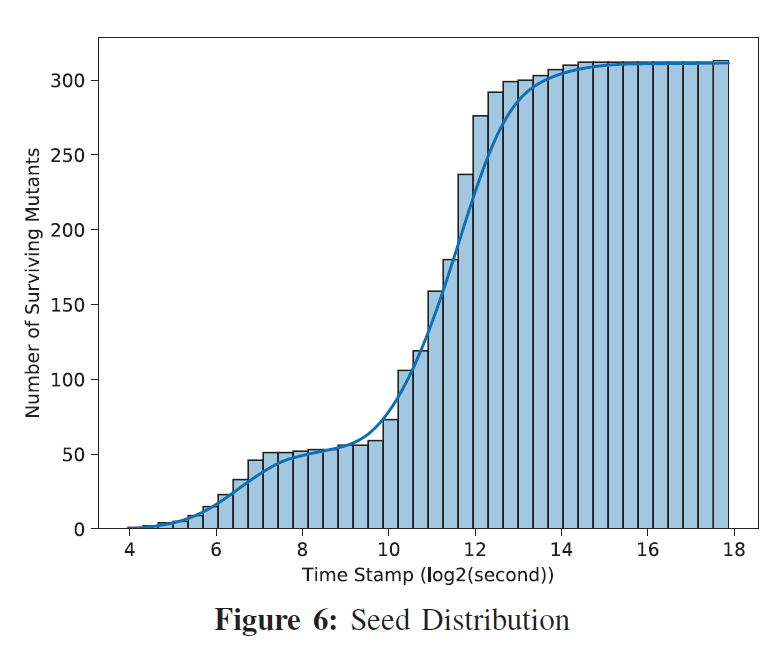
- 遗传算法的有效性:图6显示了在S2N上继续运行进化变异测试时,FAST发现的存活变异体数量的累积情况,大概在2^16秒时饱和
讨论
- 变异SPEC:目前的方法是变异code而不是SPEC,理论上是可以反过来发现同样的gap
- 然而,CODE和SPEC变异的对称性仅适用于发现SPEC中的差距,并不适用于判断差距是有意的还是错误的过程。在FAST中,可以通过对CODE变异体运行测试来对差距进行分类。但对于SPEC变异体来说,运行测试是徒劳的,因为CODE没有修改。这是FAST不采用SPEC变异方法的主要原因。
- 将对称性扩展到差距分类过程的解决方案是SPEC嵌入,即在适当的CODE位置嵌入SPEC并运行测试套件。
- 基于coverage的SPEC完备性测试工具:
- 目前流行用覆盖度(行覆盖度、指令覆盖度或分支覆盖度)来表示完整性,开源项目的谨慎维护者甚至可能要求任何新的CODE都必须附带测试用例,以保持代码库中的CODE覆盖率高。
- 目前没有用于测量SPEC的CODE覆盖度的工具,挑战在于似乎每个CODE片段都会参与到证明一些SPEC属性的过程中,很难解开复杂的逻辑公式。
- FAST的应用
- 可应用的对象具备:验证系统是完全自动化的;FAST可以修改某种形式的CODE表示(LLVM IR)
- FAST的普适性受到限制,因为形式验证尚未成为标准的工业实践,大多数软件中缺少SPEC
- 可能错过一些gap的原因:
- 变异演化方法本质上是不完整的。类似于为什么模糊测试无法找到软件中的所有错误一样,进化变异策略无法产生能够揭示SPEC中所有差距的CODE变异体——搜索空间太大无法枚举。
- 某些SPEC差距需要手动确认,特别是在第5种情况下,CODE变异体的验证失败——需要手动检查验证失败是由于不同步的证明提示(隐藏了SPEC差距)还是真正的SPEC违规引起的。
结论
本文介绍了FAST工具,用于揭示形式SPEC中的不完整问题。FAST展示了如何通过交叉检查将形式验证程序(SPEC、CODE和测试套件)中的“冗余”和“多样性”协同起来,并通过枚举和进化变异测试提供了具体的设计和实现,用于检测SPEC中的盲点。本文将FAST应用于DPN和S2N,并分别确认了它们SPEC中的13个和21个盲点。这凸显了SPEC不完整在现实世界应用中的普遍存在。作者希望FAST的发现可以一定程度上呼吁社会,引起更多关于测量和确保形式验证代码库中SPEC质量的关注。
可参考论文
mutation testing的
- Assessment of class mutation operators for c++ with the mucpp mutation system
- Users guide to the pilot mutation system
- W Eric Wong. Mutation Testing for the New Century, volume 24. Springer Science & Business Media, 2001.
- Timothy Alan Budd. Mutation Analysis of Program Test Data. Yale University, 1980.
- Pedro Reales Mateo and Macario Polo Usaola. Reducing
mutation costs through uncovered mutants. Software Testing, Verification and Reliability, 25(5-7):464–489, 2015. - Baowen Xu, Xiaoyuan Xie, Liang Shi, and Changhai Nie.
Application of genetic algorithms in software testing. In
Advances in Machine Learning Applications in Software
Engineering, pages 287–317. IGI Global, 2007.
思考
- 种子选择
- 根据适度进行排序
- 种子变异
- 可以参考具体的对运算符进行的变异策略、改变循环结构
- evmfuzz是每次变异一个位置后就执行,根据变异造成的效果改变变异器的权重;FAST是每次将所有能变异的地方进行变异,高阶变异是3个点同时变异
- 种子评估:剩余的验证错误数量和变异trace的长度,倾向于发现新的验证错误、尽可能短