Sun Y, Wu D, Xue Y, et al. GPTScan: Detecting Logic Vulnerabilities in Smart Contracts by Combining GPT with Program Analysis[C]//2024 IEEE/ACM 46th International Conference on Software Engineering ICSE, 2024.
Abstract
现有漏洞检测工具主要目标是检测出具有固定控制/数据流模式的漏洞,根据综述,80%的Web3漏洞是无法审计出的逻辑漏洞,采用GPT探索如何检测逻辑漏洞。
解决思路:静态分析+GPT(直接使用GPT进行漏洞识别误报率过高,受限于预训练知识)
漏洞划分:scenario property
Introduction
研究现状
- Do you still need a manual smart contract audit? 使用 GPT3.5(比GPT4便宜20倍) 来为项目范围的“是或否”问题提供高级漏洞描述,已经比典型的函数级漏洞检测更容易了。
- 误报率 96%
- 本文利用GPT作为代码理解工具,将漏洞类型划分为 code-level scenarios and properties
- 场景描述了在哪些代码功能下可能发生逻辑漏洞,而属性则解释了脆弱代码的特征或操作。
- 基于代码层的语义匹配候选函数中的漏洞
- 然而,由于基于GPT的匹配仍然是粗粒度的,GPTScan进一步指示GPT智能识别关键变量和语句,然后通过专门的静态确认模块进行验证。
- 智能合约项目可能由多个Solidity文件组成,直接将所有文件输入给GPT可能是不可行或成本高昂的。为了解决这个问题,GPTScan采用了多维过滤过程,有效地缩小了用于GPT匹配的候选函数范围。
- 优化后可以使用默认的4k context token size,而不需要更昂贵的16k
实现
- 大模型:GPT3.5,4K,temperature=0
- prompt:提出了一种新的mimic-in-the back ground方法,基于 zero-shot chain of- thought prompting
- 静态分析:ANTLR 和 crytic-compile
- 数据集:共400个合约项目,3000个sol文件,472k行代码
- 市值最高的 top200
- web3bugs
- Defihacks
- 相关实验结果已经开源:https://sites.google.com/view/gptscan
- rules开源:https://github.com/MetaTrustLabs/GPTScan
结果
- 发现漏洞
- 测试没有漏洞的合约 假阳率4.39%
- 测试较大的合约项目,平均精度为57.14%
- Web3Bugs:recall 83.33% ,F1分数 67.8%
- 发现了9个审计公司未发现的漏洞
- 快速 划算
- 每1000行代码平均14.39s 0.01$
- 可用性
- 已被集成到安全工具 MetaScan 中
Background
- 合约漏洞类型:参考综述Demystifying Exploitable Bugs in Smart Contracts
- 难以利用,不直接和项目相关
- 使用简单、不和项目逻辑相关的oracle即可检测
- 重入 溢出
- 业务逻辑相关的漏洞:
- 价格操纵 标识违规 错误状态更新 原子性违反 权限提升 错误accounting
- GPT在漏洞检测中的应用
- 能够理解源代码,实现zero-shot learning
- Do you still need a manual smart contract audit 用GPT-4-32k,给GPT提供漏洞描述,利用漏洞描述来检测整个项目中的漏洞,但是召回率较差
Motivating Examples
发现GPT对于“before”这个概念的理解存在困难,因此仅依靠GPT可能会将已修复版本的转账函数误报为存在漏洞。因此,静态分析是必要的。
根据上述例子,发现静态分析无法理解高级语义信息,而GPT可能会忽视一些低级信息,分别可能导致较低的召回率和较高的误报率。将这两种技术结合起来可以互补彼此,并提高检测性能。
GPTScan

蓝色 GPT模块
绿色 静态分析
输入合约/合约项目后,采用静态分析方法进行语法分析、函数调用图来判断可达性、候选函数
利用GPT将候选函数与相关漏洞类型的预抽象场景和属性进行匹配。对于匹配的函数,GPTScan通过GPT进一步识别关键变量和语句,然后将其传递给专门的静态分析模块进行漏洞确认。
挑战
- 项目中可能有很多函数,直接将所有函数作为GPT输入不现实,挑战是高效缩减候选函数的范围
- 现有的基于GPT的漏洞检测工具输入的是高层次的漏洞描述,依赖GPT对漏洞预训练的知识和推理能力,能否将漏洞类型分解,直接从语义层面理解漏洞
- GPT的输出可能是不可信赖的,如何进一步确认 匹配漏洞类型
Scenario and Property Matching
现有工具输入的漏洞描述例子
An attack where an attacker observes pending transactions and creates a new transaction with a higher gas price, enabling it to be processed before the observed transaction. This is often done to gain an unfair advantage in decentralized exchanges or other time-sensitive operations.”
方法:手动将漏洞分解为场景和属性
- 场景:逻辑漏洞可能发生时的函数功能
- 属性:漏洞代码的操作
未来可以利用GPT4,从历史报告中提取场景和属性,利用原有代码验证,不断生成新的语句,直到通过漏洞验证。但是不同漏洞类型的Prompt必须手工设计

每个scenario and property可以被划分为2类
- 对函数功能的描述
- 函数行为的描述,与漏洞的根本原因相关(如缺少安全检查)
如果满足Scenario再次发送给GPT,判断是否满足属性
匹配候选函数后,首先,仅对通过场景匹配的函数进行属性匹配。这种场景和属性的分离能够在单个提示中查询所有场景,从而节省了GPT的成本。其次,在属性匹配过程中,通过查询场景和属性的组合而不仅仅是属性本身,通过GPT对场景进行了双重确认。
考虑到GPT模型有时会提供模棱两可的答案或难以解析的文本,场景和属性匹配仅设计为是或否的问题,旨在最大限度地减少非结构化的GPT响应的影响。此外,指示GPT学习多项选择场景匹配的输出JSON格式,利用GPT的指令学习能力。
如何降低输出的随机性:设置温度,mimic in the background
多维度函数过滤
函数可达性分析
- 筛选项目文件范围:从项目范围的文件过滤开始,其中包括排除非Solidity文件,例如位于“node_modules”目录下的文件、测试文件(例如各种“test”目录中的文件)和第三方库文件(例如来自诸如“openzeppelin”、“uniswap”和“pancakeswap”等知名库的文件)。一旦这些文件被过滤掉,GPTScan就可以专注于项目的Solidity文件本身
- 筛选OpenZeppelin:除了引入lib之外,还有直接cp OpenZeppelin项目代码的部分
- 方法:分析OpenZepplin的源代码提取出API生成白名单,将候选函数和白名单对比,如果符合则筛掉
- 未来会加入基于代码克隆的筛选方法
- 特定漏洞类别的过滤:设计了基于YAML的过滤规则规范

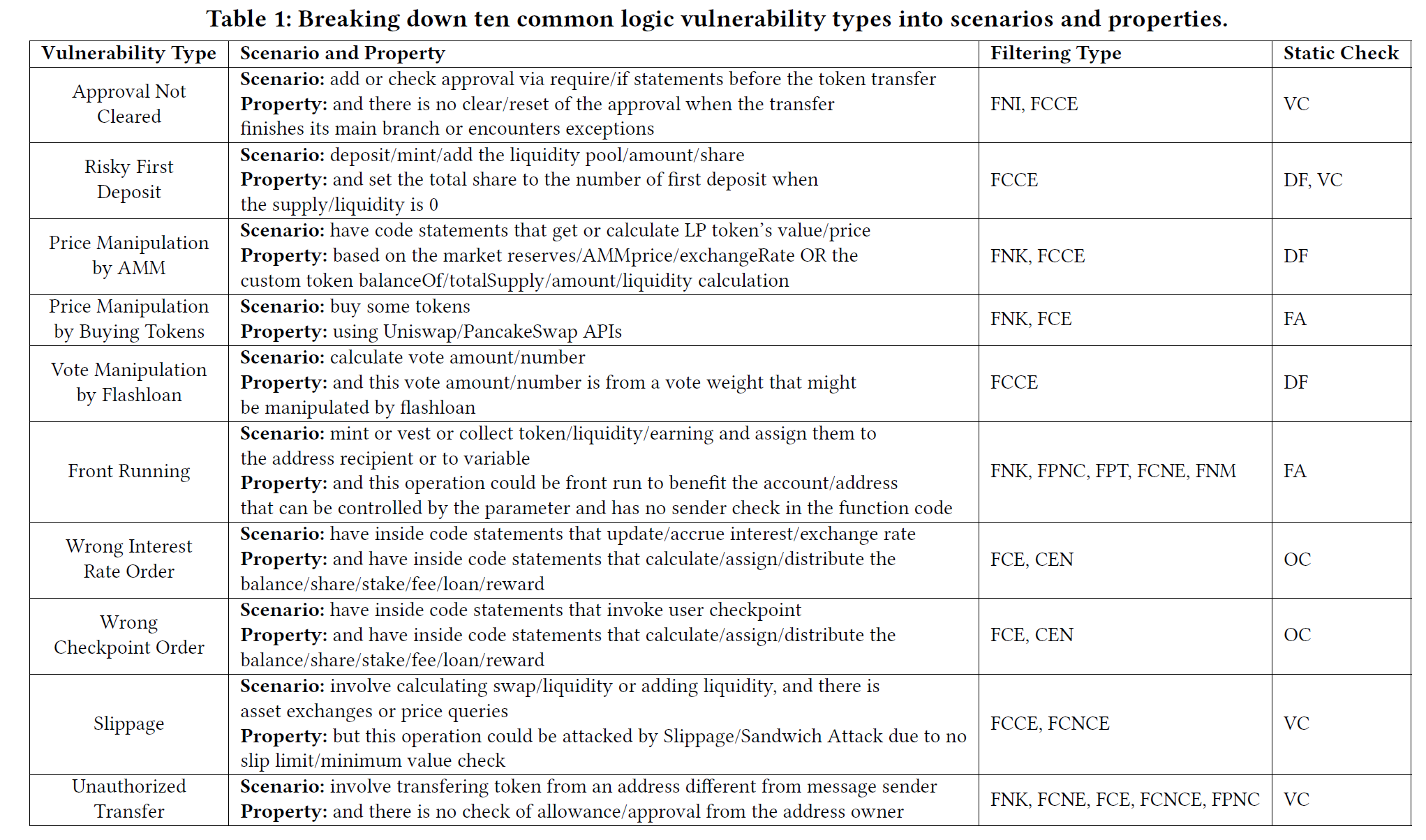
这些过滤规则涵盖了基本函数名称(FNK)、详细函数内容(FCE、FCNE、FCCE和FCNCE)、函数参数(FPT)和函数的调用关系(FPNC、FNM、CFN)。不同的漏洞将利用它们特定的过滤规则。过滤规则的选择主要基于对漏洞类型领域知识的理解。“Risky First Deposit”漏洞仅使用FCCE规则类型,选择与“total”、“supply”和“liquidity”的任意组合相关的函数,以确保存款与代币的总供应量或流动性的计算相关。另一方面,“AMM的价格操纵”与代币价格的计算有关。在这个规则中,使用FNK规则选择与价格计算相关的函数,并使用FCE规则选择包含关键字“price”、“value”和“liquidity”的函数。
可达性分析:利用call graph分析候选函数的可达性,利用ANTLR对智能合约项目的源代码进行解析,并生成抽象语法树(AST)。对于函数可见性进行分类
GPT识别和静态确认
GPT对句法可能不敏感,静态分析工具聚焦于变量和陈述
利用GPT的帮助来提取与提示中描述的特定业务逻辑相关的变量和语句的地方。有了这些变量和语句才可以使用静态分析来确认漏洞是否存在。

对于每个提取的变量或语句,GPTScan指示GPT提供一个简短的描述。这个描述有助于确定给定的变量是否与问题相关,并有助于避免错误的答案。如果GPT提供的变量或语句在函数的上下文中不存在,或者描述与问题无关,GPTScan将终止判断过程,并认为漏洞不存在。另一方面,如果提供的变量和语句经过验证,GPTScan将将它们输入静态分析工具,使用静态数据流追踪和静态符号执行等方法来确认漏洞的存在。具体而言,设计了以下四种主要类型的静态分析方法
- 静态数据流分析
- Value Comparison Check 值比较检查
- Other Check
- 函数调用参数检查
实现
GPT-3.5-turbo
ANTLR 可以不需要编译进行源代码分析
Evaluation
Top200的数据集和BlockScope类似
- 假阳率:在没有漏洞的合约集中进行测试,4.39%,web3bugs的假阳率高一些
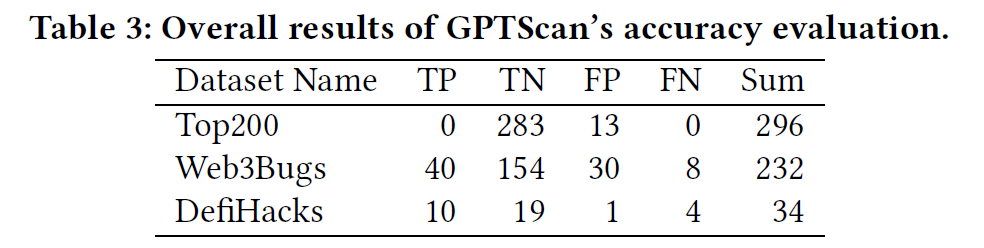
- 准确率 90% TP/TP+FP
- 12个漏报漏洞是由于缺少别名分析导致的
- 和现有静态分析对比
- Slither发现了124个误报,缺少对函数调用的考虑
- MScan 仅支持一个漏洞类型
- 和现有GPT工具对比,仅有一篇不开源的
静态分析确认部分的重要性:消融实验
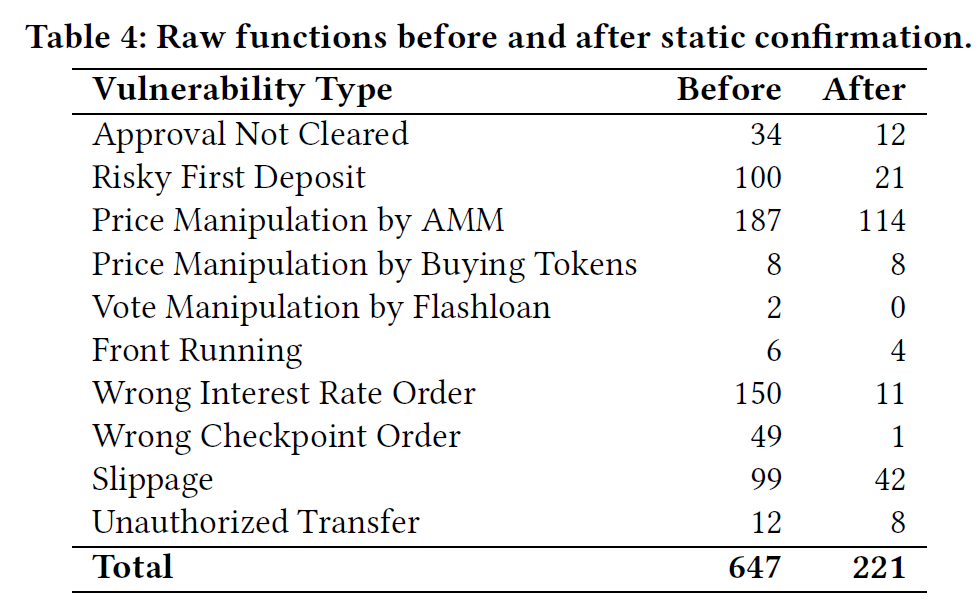
- 筛掉了假阳模块,221/647
- 也删除了3个假阴性,说明影响较小
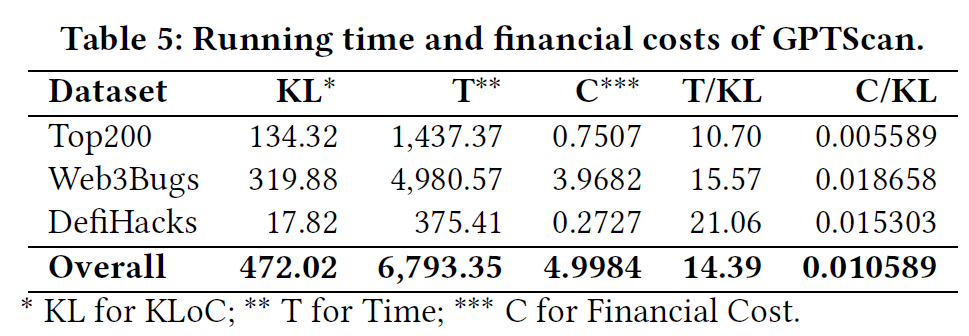
运行时间和经济开销
- tiktoken,每千行代码时间和美元
漏洞发现:9个新漏洞
Discussion
局限性
- 修饰符 过滤是白名单机制,没有利用语义分析(代码克隆)
- 对控制流和数据流分析的方法对路径不敏感,可能引入符号执行
使用其他大模型
- GPT4:提升不明显,开销增加20倍
- 调参:temperature = 0?越高越有创造力
- Google Bard, Claude self-trained LLaMA
Related work
静态分析
符号执行
动态分析
形式化验证
基于NLP的工作
Conclusion
本文提出了GPTScan,第一个将GPT与静态分析相结合的工具,用于智能合约逻辑漏洞检测。GPTScan利用GPT根据代码级别的场景和属性匹配候选的易受攻击函数,并进一步指导GPT智能识别关键变量和语句,然后通过静态确认进行验证。实验部分在三个不同的数据集上进行了评估,涵盖了约400个合约项目和3K个Solidity文件,结果显示GPTScan对于代币合约实现了高精确度(超过90%),对于大型项目实现了可接受的精确度(57.14%),并且在检测真实逻辑漏洞的召回率超过70% 。GPTScan快速、经济高效,并且能够发现被人工审计人员忽略的新漏洞。
Testing
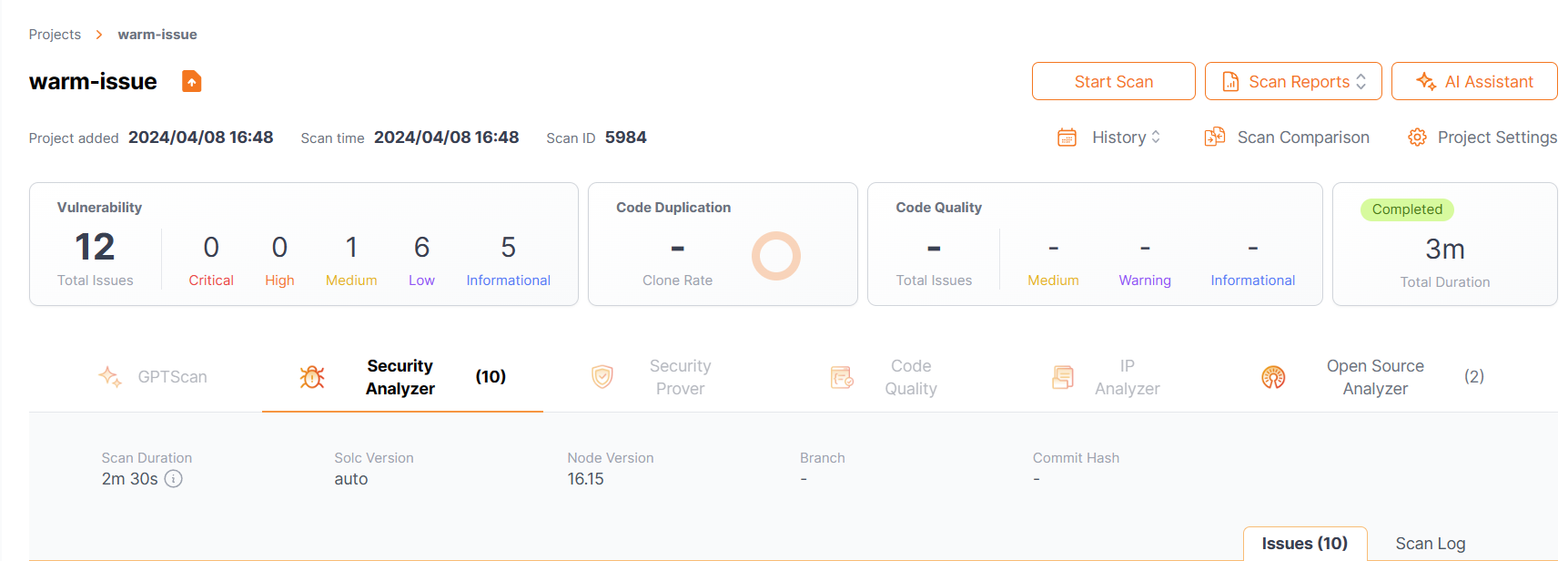
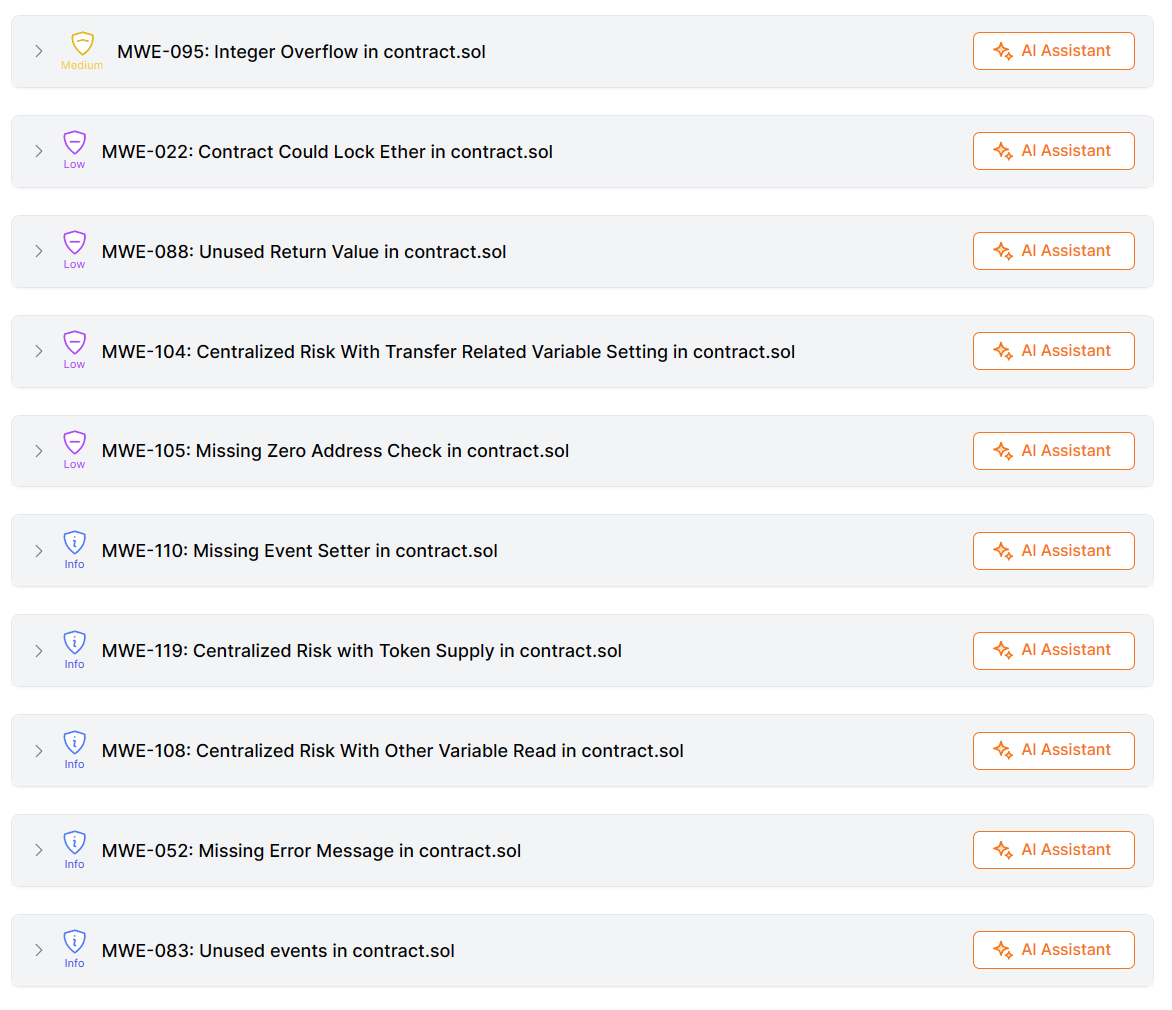
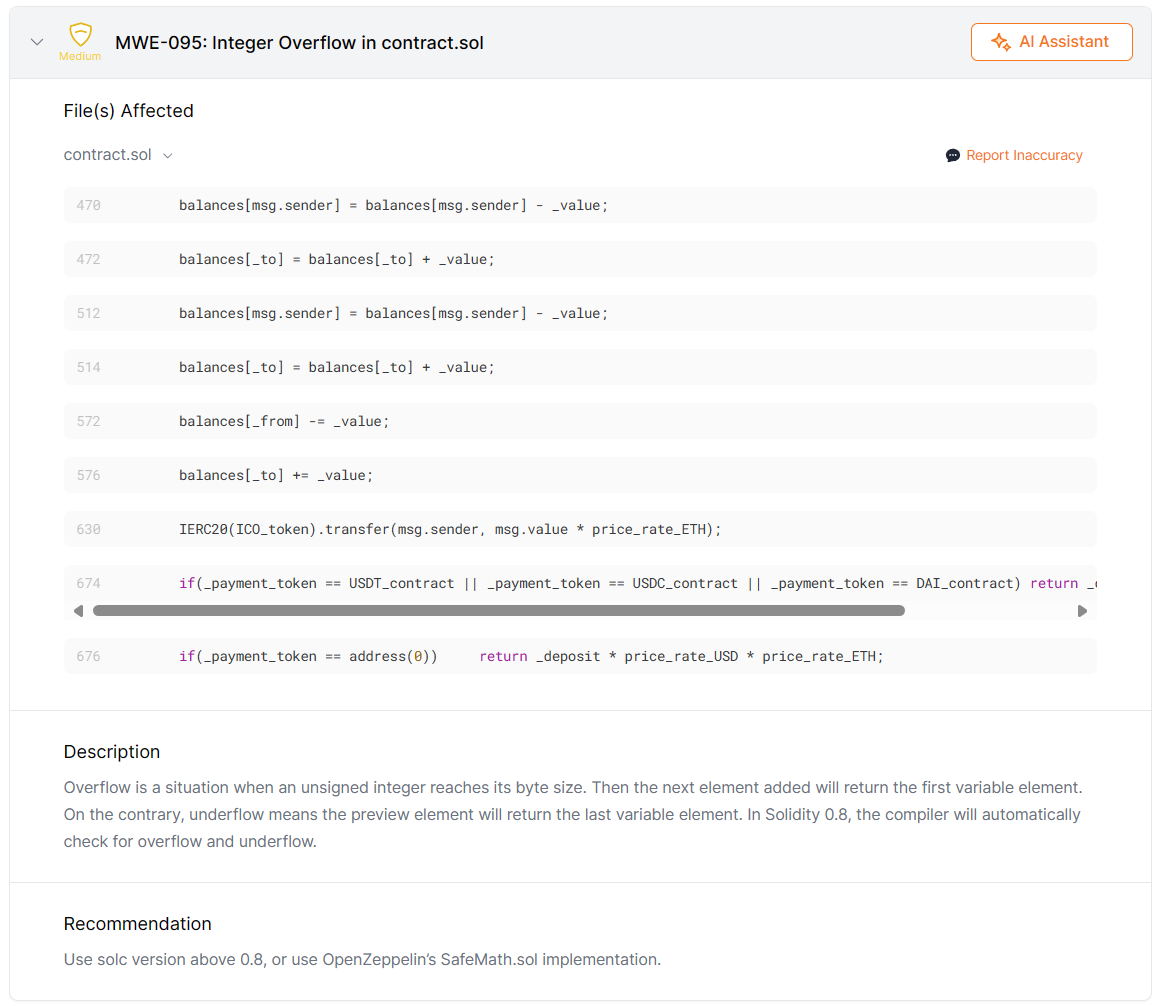
学术报告
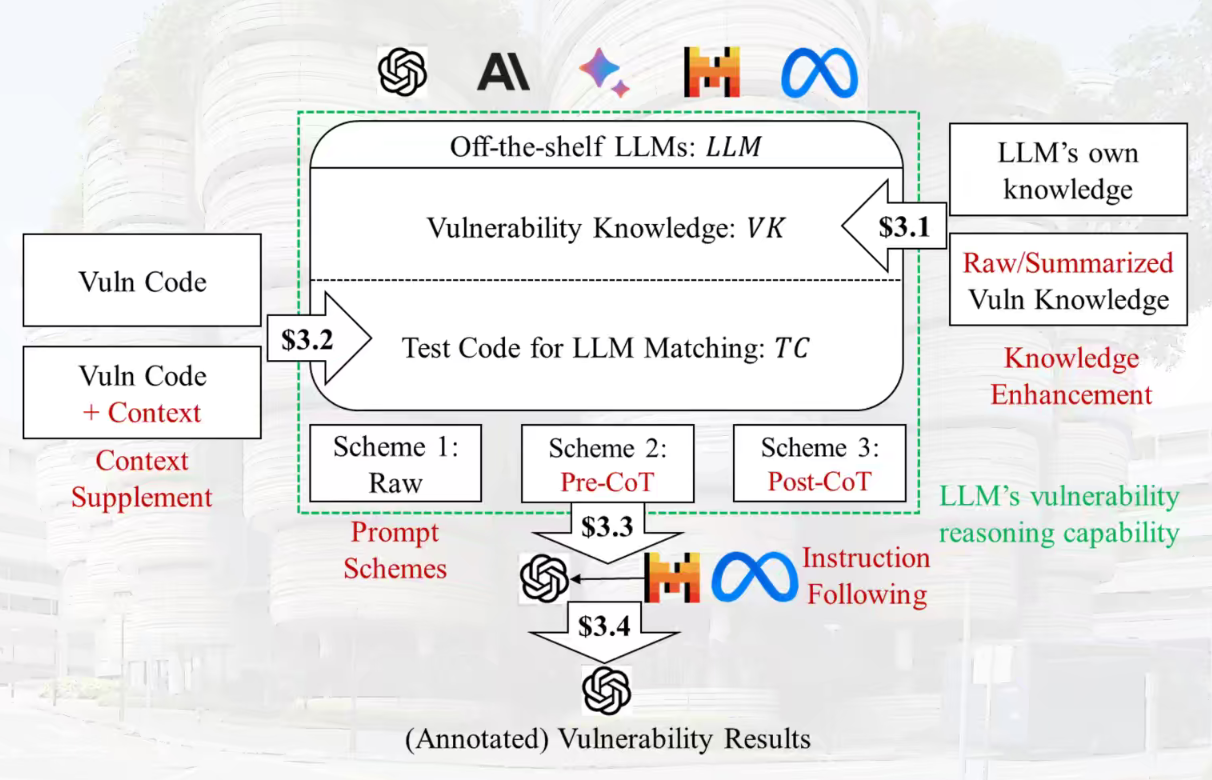
Code lama
知识生成
- 没有额外知识
- 相关漏洞报告 code4rena比赛
- 整理过的漏洞描述
审计报告一般有代码和描述
基于代码相似度进行匹配
Tool former