Ron J, Soto-Valero C, Zhang L, et al. Highly Available Blockchain Nodes With N-Version Design[J]. IEEE Transactions on Dependable and Secure Computing, 2023.
My TLDR:现有区块链节点由软件实现,区块链节点可能宕机,本文利用以太坊节点多种实现的现状,结合N-Version理论,设计了容错机制,实验证明能够抵抗错误注入攻击
Introduction
Avizienis 的 N-Version Programming (NVP,N-版本编程) 是一种 容错软件设计 方法,由计算机科学家 Algirdas Avizienis 在 1977 年提出。该方法的核心思想是通过冗余和多样性来提高软件的可靠性和容错能力。其中,同一个 SPEC 的不同实现称为 Version。
请求路由、错误处理、响应比较和排序
实验测量响应的延迟和正确性,和未修改的原始实现进行对比可用率,实验验证了额外的资源开销
Background
Blockchain
区块链网络结构
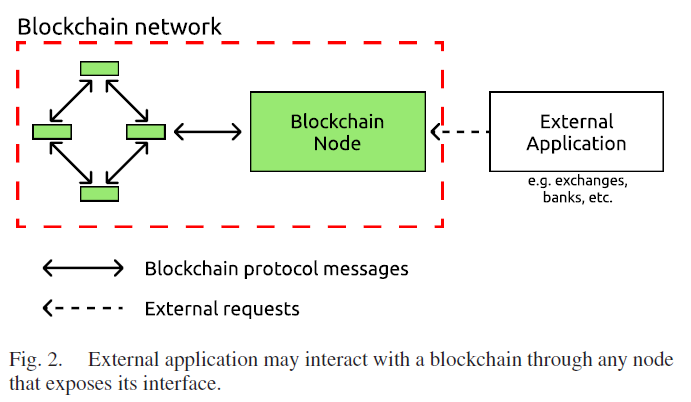
将RPC方法简化为两类:查询区块链历史信息以及发送新交易
RPC请求和响应的例子

N-Version Design
$N$个同一个规范的不同实现,为了提升软件的可靠性、性能或安全性
基本做法是比较或匹配$N$个程序的输出
一般来说,N-Version编程要求不同团队独立开发,设计、编程语言、软件栈相互独立
然而,在没有协调的情况下,由于市场竞争、优化、争议的设计理念等因素,现实中自然产生了同一个规范的不同实现(浏览器)
idea:利用已有的多种实现,称之为 自然N-Version设计

Highly Available Blockchain Node
Availability Definition
- Available:响应即时、一致(compliant)、正确
- Degraded: 响应即时,但是不一致或不新鲜
- Unavailable:不及时响应或拒绝
Timeliness 定义为 $T$ 时间内获取响应
Compliance 定义为返回的响应是否符合API中的定义
Freshness 定义为是否为最新的状态,实现上是比较最新的区块链号和外部oracle的距离
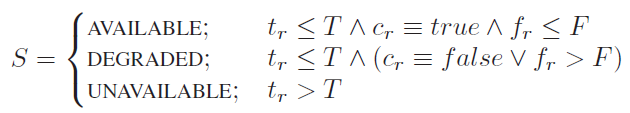
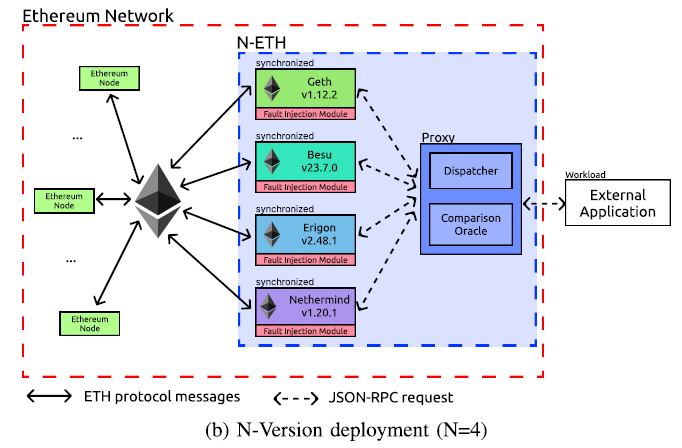
Architecture of N-V Node
N-Version Node包括$N$个子节点和一个代理
代理负责根据动态优先级策略将请求路由到子节点
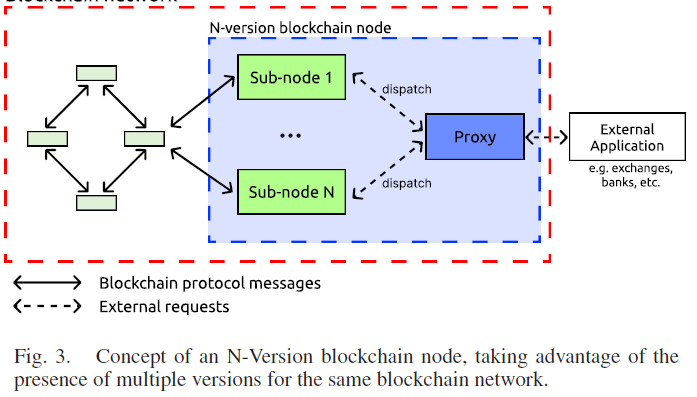
Dispatching Policy
根据稳定性负载均衡,分配给最可靠的子节点
做法:为每个子节点维护可用性分数,成功请求数/总的请求数
对所有子节点进行降序排序
Proxy收到请求后,转发给排名第一的子节点
如果子节点成功则立刻返回,否则保存response,尝试排名第二的节点
直到产生可用回复或所有节点返回一致的结果
Comparison Oracle
当没有子节点可用时,需要选择degraded中最好的响应进行返回
选择规则:
- 一致性强于不一致的响应
- 最新鲜的一致性响应
Implementation
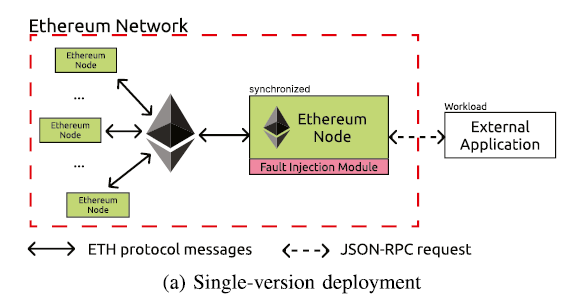
实现了原型N-ETH
GETH v1.12.2, BESU v23.7.0, ERIGON v2.48.1,NETHERMIND v1.20.1
Experimental protocol
- RQ1: 区块链节点的不确定性会导致什么结果
- 做法:system-call错误注入
RQ2: 传统区块链节点在错误注入下的可用性
- N=1
RQ3: N-version 节点提升了多少可用性
- 注入错误,变化N,最大测试到29
Workload(输入)
测试的输入是任意数量的JSON-RPC调用,测量响应的一致性、新鲜性和延迟
两个workload集
- 360000个RPC调用,每个调研的方法名和参数从21个方法的池子中来,查询当前和历史的区块链状态
- 360000个类似的RPC调用,查询当前最新的区块,收集新鲜性信息
Fault Injection
区块链节点运行在操作系统上,其运行环境可能出现错误 (网络、硬件等),传递给上层的区块链节点的就是 system_call,因此考虑对区块链软件传入错误
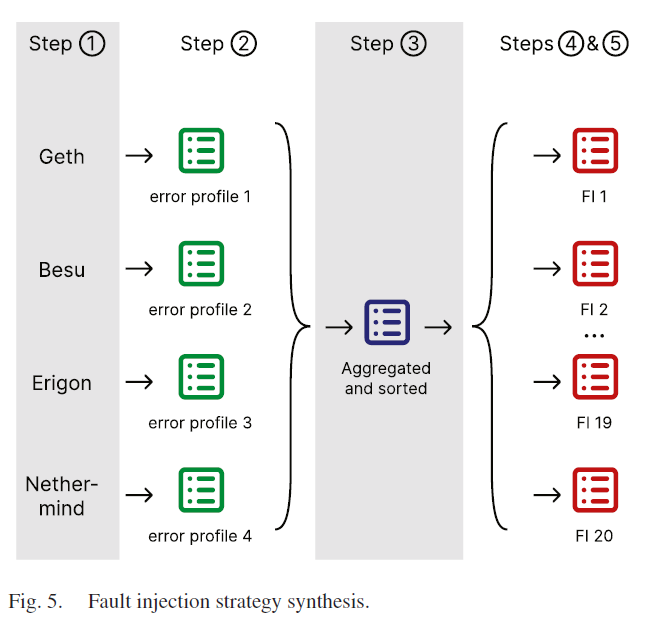
- 记录所有版本的区块链节点的
system_call以及对应的返回值 - 收集
system_call信息为集合, $ - 聚合不同版本节点的集合,$f$ 取相同name的最小值,根据 $f$ 降序排序
- 取 $n$ 个子集,$top-n$,每个集合包含最前$n$的元素
- $f$ 放大5%
获得了20个错误注入策略
- 已知(从真实信息中提取)
节点在以太坊主网进行实验,挑战
- 物理资源:2TB、16GB RAM
- 共识层客户端
- 需要10+小时的同步
- 660个以太坊节点
仅有一个clean copy,具体实验是复制这个节点的数据,实验开销为 $10,000
Experimental Results
节点受到错误注入后的错误情况
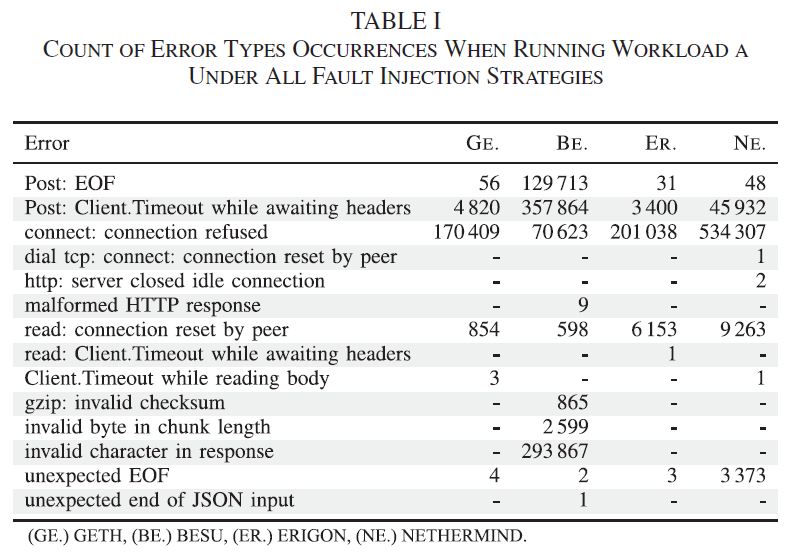
观察到 同一个错误对不同版本的影响不同
三大类错误:network issues, timeouts, or data corruption
发现有5种错误仅出现在一个版本中,说明了多样化的实现会导致多种错误,与N-Version的设计假设吻合
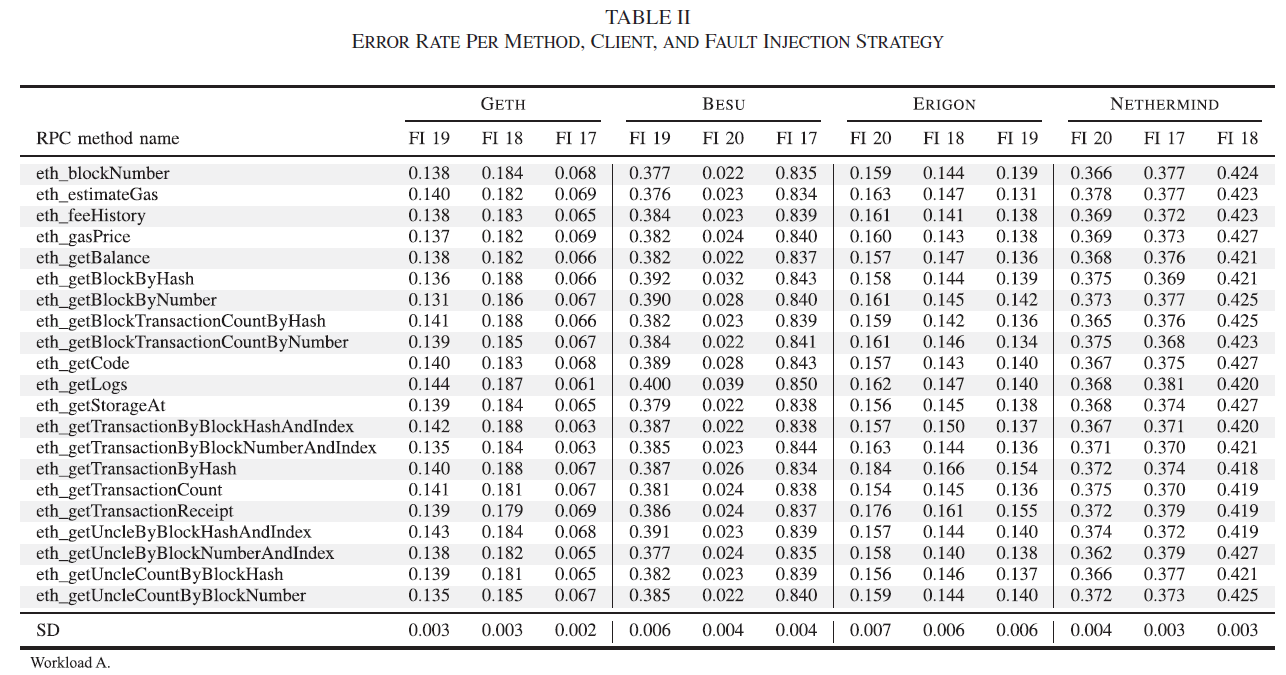
给出了指在某个错误注入策略下出现错误的RPC调用的占比
标准差很低,表明不同策略在同一个版本上的效果统一,即和方法无关,其他的16个策略在github仓库.
RQ1确认了进行N-version设计的假设:不是所有的子节点同时都会down
不同版本节点的可用性
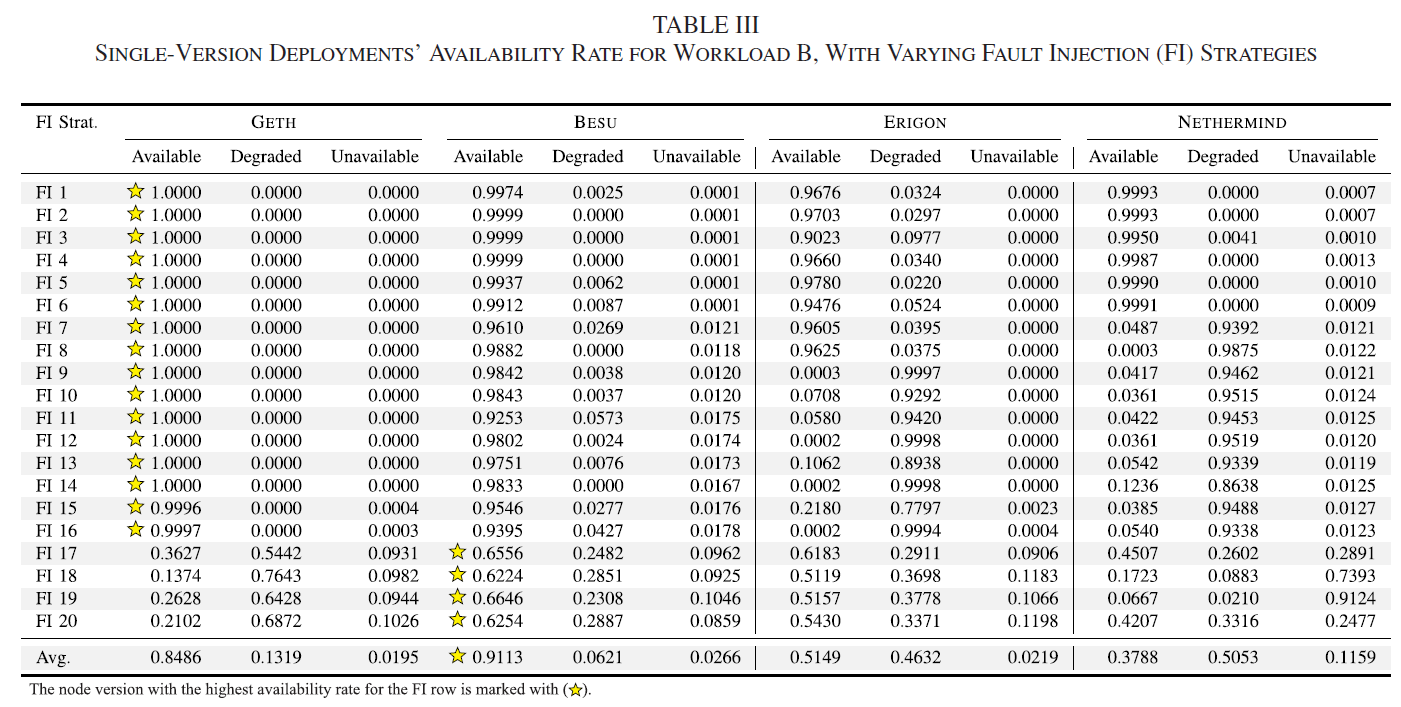
黄色星星是可用性最高的版本
Geth能够在前16个策略都保持较高可用性,然而Nethermind和Erigon 在FI7丧失可用性
平均,GETH’s availability drops to 0.8486; BESU’s availability drops to 0.9113; ERIGON’s availability drops to 0.5149; NETHERMIND’s availability drops to 0.3788
N-version 能够如何提升可用性
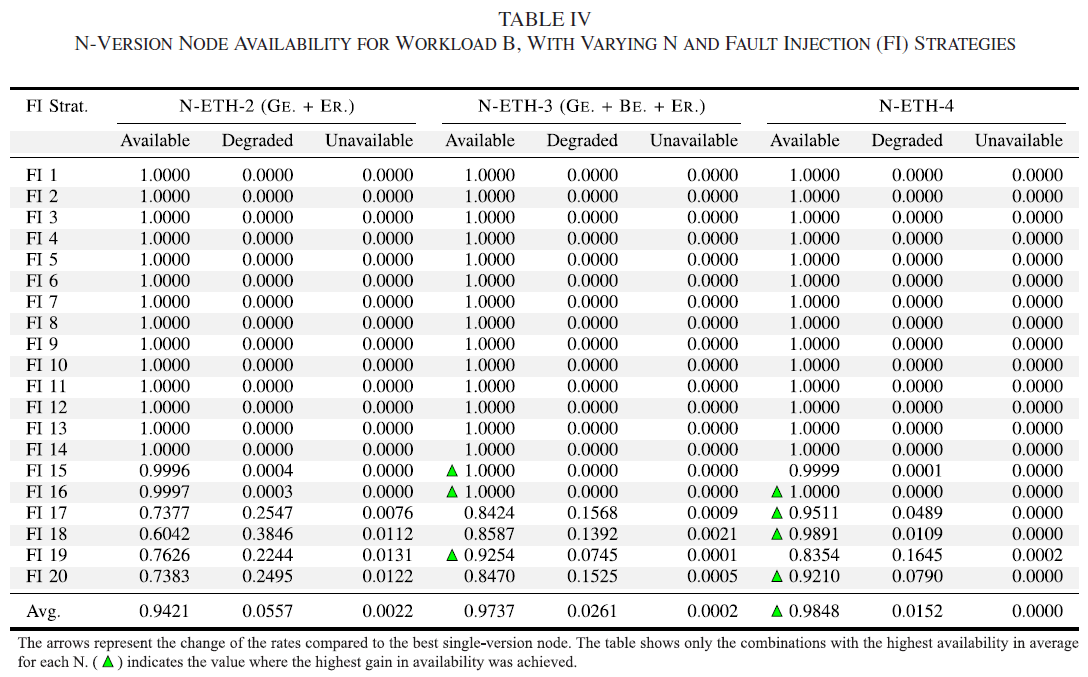
对比实验,N=4时 98.5% full availability, and 99.9999% 可用+退化的可用性
给出了资源消耗
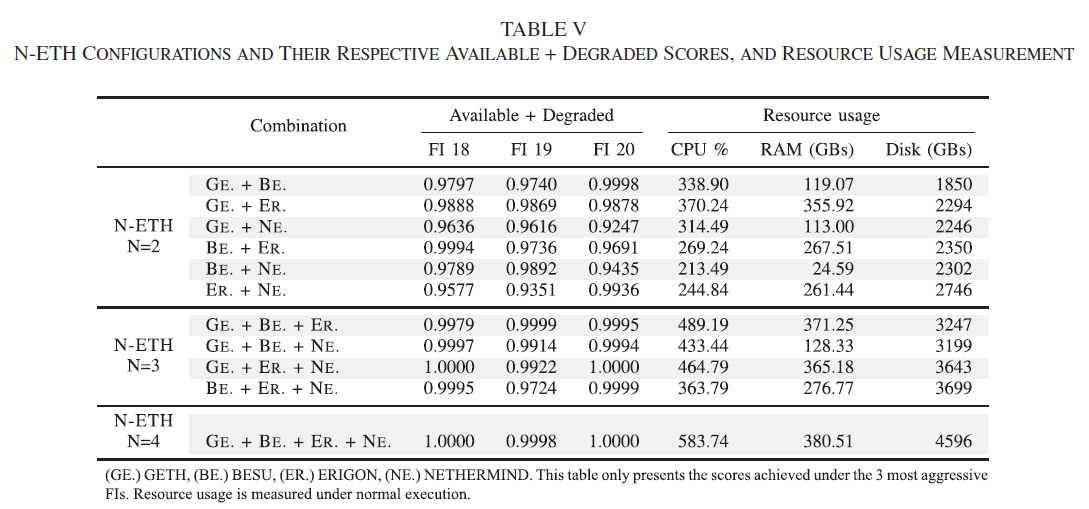
可用性增长 84.7%->98.5%
Discussion
本质是冗余提升可用性,但是对于节点服务提供商而言,性能不是问题
多个RPC的构造
My Discussion
Q
- 作为P2P网络,有共识机制保障,单个节点的宕机并不重要,本协议的受众实际上是对自己节点可用性要求非常高的用户,势必带来了额外的计算/存储开销
- 本文最核心的idea是利用了以太坊现有的多种实现的现状
- 为什么不是vote?而是排序,最多带来N开销
pros
- 提升了区块链节点服务的可用性
cons
- 如果少数节点返回了正确结果,整个框架如何响应?(For example: geth:besu:nethermind=1:1:1, geth and besu return same but wrong response, while only nethermind gives correct response)